
统计所有小于非负整数 n 的质数的数量。
示例:
输入: 10
输出: 4
解释: 小于 10 的质数一共有 4 个, 它们是 2, 3, 5, 7 。
解法一,暴力法:
class Solution:
def countPrimes(self, n: int) -> int:
count = 0
for i in range(n):
if self.isPrime(i):
count += 1
return count
def isPrime(self, n) -> bool:
if n < 2:
return False
if n == 2:
return True
i = 2
while i <= int(n ** 0.5):
if n % i == 0:
return False
i += 1
return True
其中这里利用了一个数学规律:
假设一个数 N 他有两个约数 a、b,当 a = b 时,那么它是一个合数,也就是 a^2 = N。
如果他的这两个约数都大于 根号 N ,也就是 a > 根号 N,那么一定有 a ^ > N。
所以若 N 不是质数,那么必定存在一个约数小于等于根号 N(1 除外)。
虽然利用了数学规律,但是暴力法超时了 🤪。
解法二,埃拉托色尼筛网法:
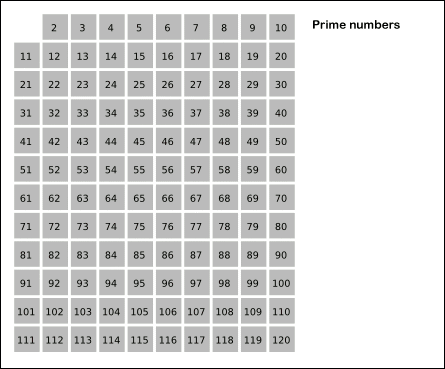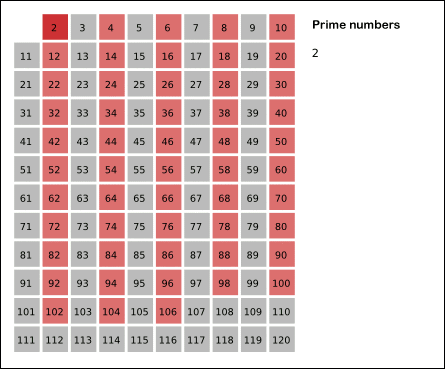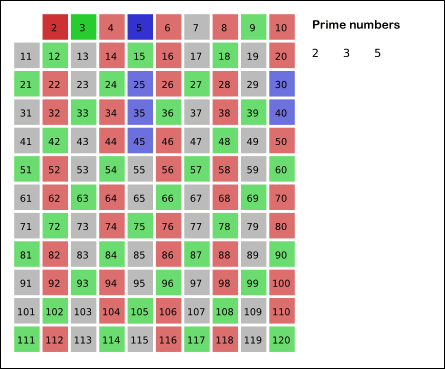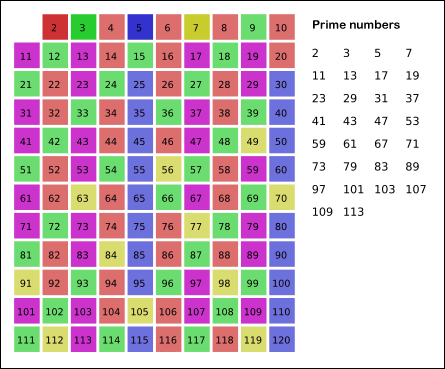
如 GIF 所示,首先筛选小于 N 的 2 的倍数,他们必定不是质数。然后筛选 3 的倍数、5 的倍数、7 的倍数 … 以此类推。剩下的数就是质数了。
class Solution:
def countPrimes(self, n: int) -> int:
if n <= 2:
return 0
arr = [1] * n
for i in range(2, n):
j = 2
mul = i * j
while mul < n:
arr[mul] = 0
j += 1
mul = i * j
return sum(arr[2:])
虽然利用了算法,但是还是超时了 🥶。
尝试用 Python 中的切片优化一下,把原来的顺序赋值为 0 改为批量赋值为 0:
class Solution:
def countPrimes(self, n: int) -> int:
if n <= 2:
return 0
arr = [1] * n
for i in range(2, int(n)):
if arr[i] == 1:
arr[2*i:n:i] = [0] * len(arr[2*i:n:i])
return sum(arr[2:])
我们发现在上面的筛法中有的数字是多个质数的倍数,也就是说它可能会被重复计算多次,比如说6 同时是 2 与 3 的倍数,它在计算时就被访问了两次,所以应该还有优化的空间。
所以在网上看到了一种算法,欧拉函数线性筛法。又是数学,高数要回去重新学了 😵。
这里放一下链接🔗,感兴趣的可以自己去看看。
这道 leetcode 题虽然是标着是简单的,我也觉得并不简单。
《Distributed systems theory for the distributed systems engineer》
作者在文章中提到了,分布式系统理论有很多:
…
但是往往上面罗列出来的理论都是非常深奥,复杂都需要非常认真花很多时间去理解和学习,但是往往去学习这些理论知识的学习方向恰恰不是那么的好(除非你是作为博士或研究生去学习)。
所以,分布式系统工程师到底需要学习那些分布式理论知识?
首先,我们需要学习和阅读一些书籍,去了解分布式系统工程师在构建分布式系统过程中,会遇到的一些难点、问题,为后面更加复杂的分布式问题细节研究打下基础,作者也罗列了一些文内容,这里就不详细介绍只把他们列出来。
然后提到了设计分布式系统需要知道的一些基本知识和需要做的东西,如故障检测、弹力设计,与一致性相关的二阶段提交、三阶段提交,还有 Gossip 算法,还有 CAP 定理等等。
这些都是我架构师成长之路上的必经学习之路啊 🎓,需要慢慢去消化吸收了。
这里分享 Python 的两个工具函数,一个是利用线程池将某个函数转换为 Python 的异步函数,返回一个协程对象。另一个是将异步函数转换为同步函数,将其结果直接返回。
import functools
def force_async(fn):
"""
turns a sync function to async function using threads
"""
from concurrent.futures import ThreadPoolExecutor
import asyncio
pool = ThreadPoolExecutor()
@functools.wraps(fn)
def wrapper(*args, **kwargs):
future = pool.submit(fn, *args, **kwargs)
return asyncio.wrap_future(future) # make it awaitable
return wrapper
def force_sync(fn):
"""
turn an async function to sync function
"""
import asyncio
@functools.wraps(fn)
def wrapper(*args, **kwargs):
res = fn(*args, **kwargs)
if asyncio.iscoroutine(res):
return asyncio.get_event_loop().run_until_complete(res)
return res
return wrapper
他们两个分别有什么用呢?
举个例子,当我们用到一些第三方的库,他会调用 IO,比如网络请求,文件读取等等。我们在一些类中需要将类抽象为异步函数,抽象的方法返回的结果必须是一个 awaitabale对象即协程,但是我们调用的库恰好是同步的,这时候就可以利用第一个装饰器。
第二个装饰器可以利用在测试中,比如某个函数它是异步的,我们需要在 setup_* 中调用,那么我们就可以利用装饰器将其变为同步函数。
他们的实现原理非常简单,force_async 是利用线程池实现的,force_sync 则是将异步函数在事件循环中执行完后将结果返回。
不要尝试去避免故障,而是要把处理故障的代码当成正常的功能坐在架构里写在代码里。
