
由于最近在工作中在做 Service Mesh 的落地项目,有非常多的感触,所以想写一篇文章来分享这个「新一代的微服务架构 Service Mesh」。
笔者会从以下顺序开始分享:
首先会从 「单体应用架构」 演进到 「微服务架构」 产生的问题开始说起,到自己作为开发人员感触最深的痛点。
然后简单介绍以下今天的主角 Istio 的服务编排环境 Kubernetes。
最后从 Sidecar 这种设计,说到 Service Mesh,最后到我们的主角 Istio。
到正式的主角之前的铺垫会比较多,这是为了让大多数开发者都能理解。
本文大部分内容都整理自笔者的学习资料加上自己的一些总结和体会,大家最后可以从文末找到他们。
从「单体」到「分布式」演进(也就是微服务化)的原因我相信大家都很了解了。
因为业务量越来越大,我们需要多台机器才能应对大规模的应用,所以需要垂直或者水平拆分业务系统,让其变成一个分布式的架构。
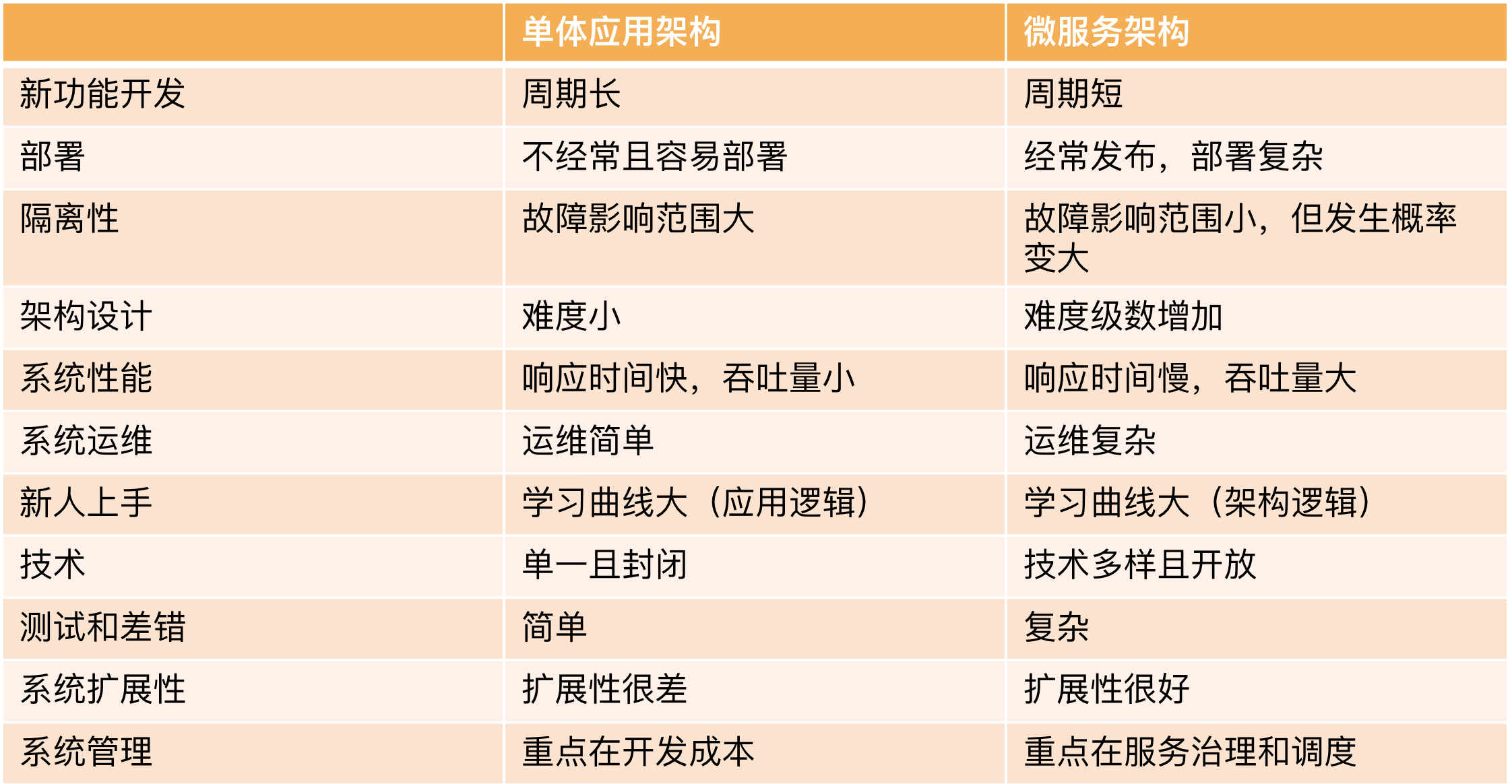
从上面的表格我们可以看到,分布式系统虽然有一些优势,但也存在一些问题。
作为业务开发人员最直观的感受:
总结来说,微服务架构有这些痛点和需要解决的问题:

图片引用自 《左耳听风 - 分布式系统技术栈》
针对这么多的需要去解决和处理的问题。
引出了我们今天的主角 Istio。
在介绍我们今天的主角 Istio 之前,先简单介绍一下它的服务编排环境 Kubernetes。通过 Docker 以及其衍生出来的 Kubernetes 之类的软件或解决方案,大大地降低了做上面很多事情的门槛。
Docker 相信大家都非常了解了,所以这里我就从 Docker 过度讲到 k8s。
Docker 容器这个听起来玄而又玄的概念,实际上是在创建容器进程时,指定了这个进程所需要启用的一组 Namespace 参数。这样,容器就只能“看”到当前 Namespace 所限定的资源、文件、设备、状态,或者配置。而对于宿主机以及其他不相关的程序,它就完全看不到了。
int pid = clone(main_function, stack_size, CLONE_NEWPID | SIGCHLD, NULL);
我们知道,在 Linux 系统中创建线程的系统调用是 clone(),就像这样。而当我们用 clone() 系统调用创建一个新进程时,就可以在参数中指定 CLONE_NEWPID 参数。这时,新创建的这个进程将会“看到”一个全新的进程空间,在这个进程空间里,它的 PID 是 1。之所以说“看到”,是因为这只是一个“障眼法”,在宿主机真实的进程空间里,这个进程的 PID 还是真实的数值,比如 100。
所以说,容器,其实是一种特殊的进程而已。
感兴趣的同学可以阅读 《自己动手写 Docker》 和尝试一下书中的代码。
我花了很多精力去学习 Linux 容器的原理、理解了 Docker 容器的本质,终于, Namespace 做隔离, Cgroups 做限制, rootfs 做文件系统” 这样的“三句箴言”可以朗朗上口了。
为什么 Kubernetes 又突然搞出一个 Pod 来呢?
这里提一个概念: Pod, 是 Kubernetes 项目中最小的 API 对象。如果换一个更专业的说法,我们可以这样描述: Pod 是 Kubernetes 项目的原子调度单位。
这里通过一个实际的例子来说明:
我们通过 pstree 查看操作系统中运行的进程,进程并不是“孤苦伶仃”地独自运行的,而是以进程组的方式,“有原则地”组织在一起。
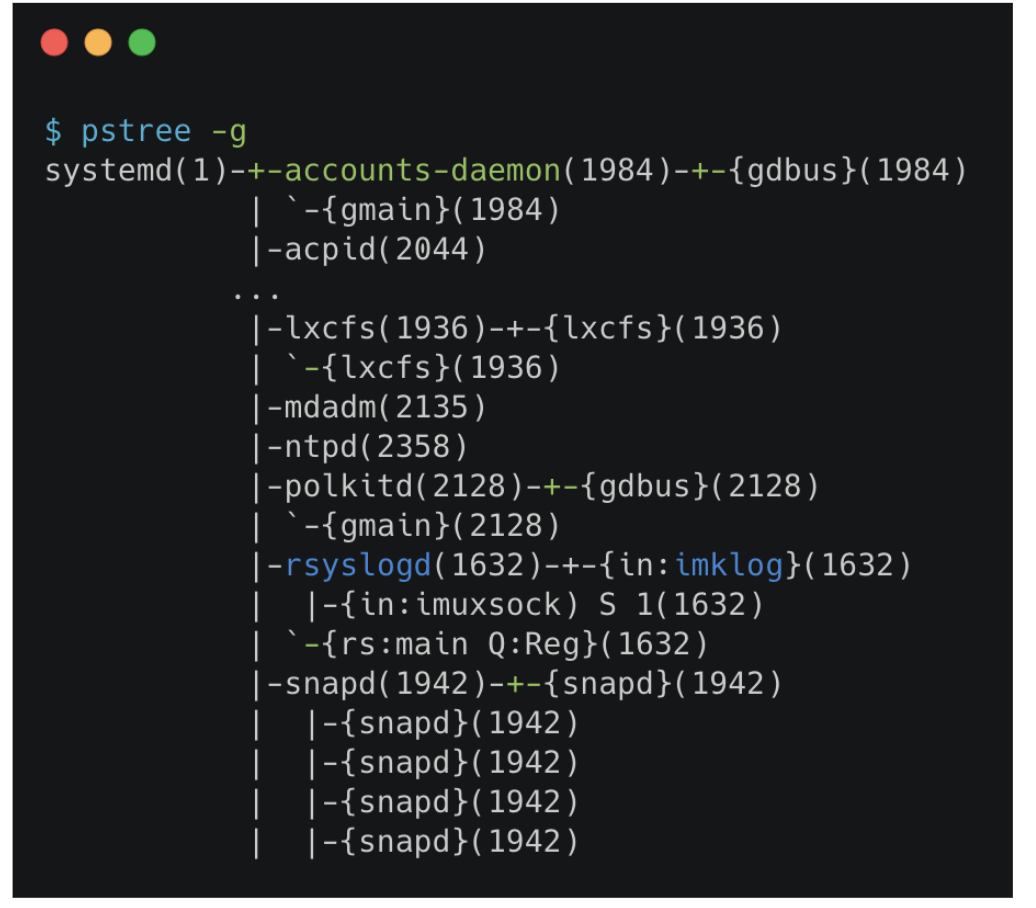
比如,这里有一个叫作 rsyslogd 的程序,它负责的是 Linux 操作系统里的日志处理。可以看到, rsyslogd 的主程序 main, 和它要用到的内核日志模块 imklog 等,同属于 1632 进程组。这些进程相互协作,共同完成 rsyslogd 程序的职责。
如果说 「Docker 容器」的其实就是一个「特殊的进程」。
那么「K8s」就可以理解成操作系统。
Kubernetes 所做的,其实就是将 “进程组” 的概念映射到了容器技术中,并使其成为了这个云计算 “操作系统” 里的 “原子调度单位”。
不过,相信此时你可能会有第二个疑问:
对于初学者来说,一般都是先学会了用 Docker 这种单容器的工具,才会开始接触 Pod。而如果 Pod 的设计只是出于调度上的考虑,那么 Kubernetes 项目似乎完全没有必要非得把 Pod 作为“原子调度单位”吧?
首先,关于 Pod 最重要的一个事实是:它只是一个逻辑概念。
具体的说: Pod 里的所有容器,共享的是同一个 Network Namespace,并且可以声明共享同一个 Volume。
那这么来看的话,一个有 A 和 B 两个容器的 Pod,不就是等同于一个容器(容器 A)共享另外一个容器(容器 B)的网络和 Volume ?这好像通过 docker run --net --volumes-from 这样的命令就能实现,就像这样。
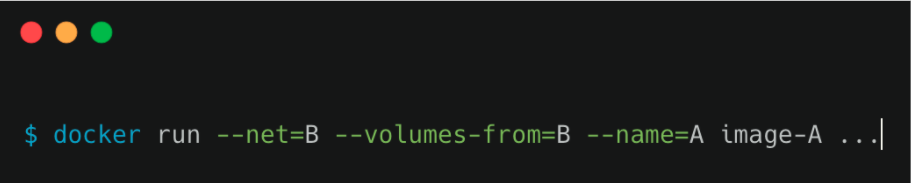
但是,你有没有考虑过,如果真这样做的话,容器 B 就必须比容器 A 先启动,这样一个 Pod 里的多个容器就不是对等关系,而是拓扑关系了。
所以,在 Kubernetes 项目里, Pod 的实现需要使用一个中间容器,在这个 Pod 中,中间容器永远都是第一个被创建的容器,而其他用户定义的容器,则通过 Join Network Namespace 的方式,与 中间容器关联在一起。

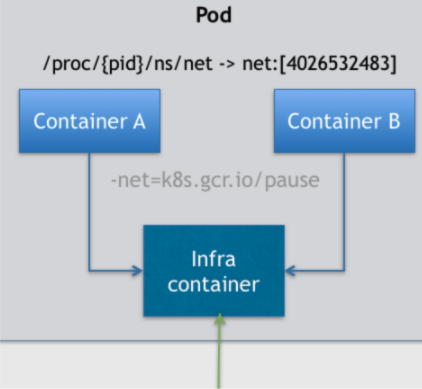
如上图所示,这个 Pod 里有两个用户容器 A 和 B,还有一个中间容器容器。很容易理解,在 Kubernetes 项目里,中间容器一定要占用极少的资源,所以它使用的是一个非常特殊的镜像,叫作: k8s.gcr.io/pause。这个镜像是一个用汇编语言编写的、永远处于“暂停”状态的容器,解压后的大小也只有 100~200 KB 左右。
这里就不再深入说明了,感兴趣的可以点击图片链接,或者在文章末尾我列出的参考资料。
其中 Pod 的一个重要的特性,它的所有容器都共享同一个 Network Namespace。这就使得很多与 Pod 网络相关的配置和管理,也都可以交给 Sidecar 完成,而完全无须干涉用户容器。
这里最典型的例子莫过于 Istio 这个微服务治理项目了。
接下来就从 Sidecar 到 Service Mesh 来一步一步介绍 Istio 的设计思想。这里提到的 Sidecar 到底是什么呢, Sidecar 在国内翻译为边车模式,这个翻译真的很形象。
所谓的边车模式,对应于我们生活中熟知的边三轮摩托车。

图片引用自 《左耳听风 - 管理设计篇“边车模式”》
我们可以通过给一个摩托车加上一个边车的方式来扩展现有的服务和功能。这样可以很容易地做到 “控制 “ 和 “逻辑” 的分离。
也就是说,我们不需要在服务中实现控制面上的东西,如监视、日志记录、限流、熔断、服务注册、协议适配转换等这些属于控制面上的东西,而只需要专注地做好和业务逻辑相关的代码,然后,由“边车”来实现这些与业务逻辑没有关系的控制功能。
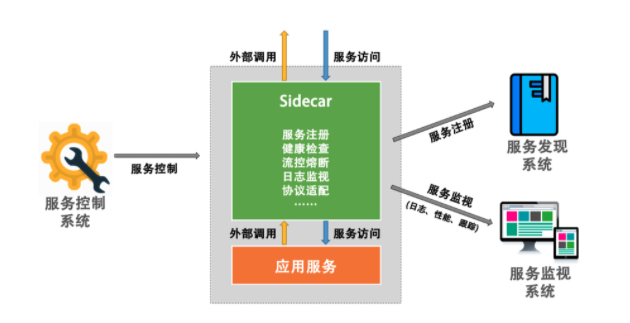
图片引用自 《左耳听风 - 管理设计篇“边车模式”》
那最终这个 Sidecar 的效果就会像上图所示。
那么在 Istio 中, [Envoy](https://github.com/envoyproxy/envoy) 就是默认的 Sidecar。它与服务容器在同一个 Pod 中,与服务容器共享同一个 Network Namespace,接管所有经过服务容器的流量。
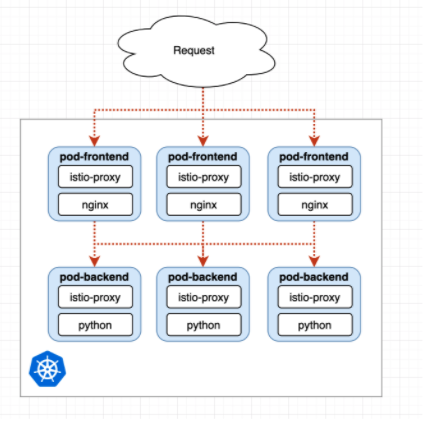
然后, Sidecar 集群就成了 Service Mesh。图中的绿色模块是真实的业务应用服务,蓝色模块则是 Sidecar, 其组成了一个网格。而我们的应用服务完全独立自包含,只需要和本机的 Sidecar 依赖,剩下的事全交给了 Sidecar。
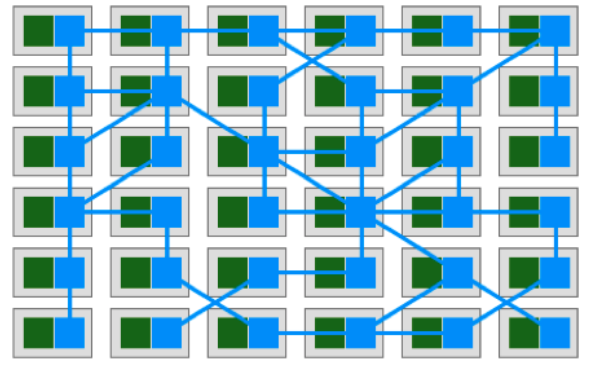
图片引用自 《左耳听风 - 管理设计篇之“服务网格”》
Service Mesh 这个服务网络专注于处理服务和服务间的通讯。其主要负责构造一个稳定可靠的服务通讯的基础设施,并让整个架构更为的先进和 Cloud Native。在工程中, Service Mesh 基本来说是一组轻量级的服务代理和应用逻辑的服务在一起,并且对于应用服务是透明的。
说白了,就是下面几个特点。
Service Mesh 是一个基础设施。Service Mesh 是一个轻量的服务通讯的网络代理。Service Mesh 对于应用服务来说是透明无侵入的。Service Mesh 用于解耦和分离分布式系统架构中控制层面上的东西。我们今天的主角 Istio,它的伟大之处不只是在设计本身,而是在于它是一个兼容并包的生态。它为整个行业提供了一种全新的开发及运维的方式。
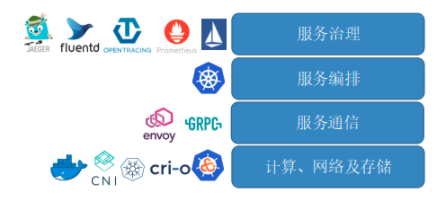
微服务架构在网络链路上还有很多待解决的点,如链路跟踪、分布式日志、监控报警、压测演练、故障注入等。若让 Istio 官方来实现所有的功能,不仅耗时,还会让整个系统变得非常臃肿。
接下来就用 Istio 的官方 Demo 来讲一个实际的应用场景。
这部分会用 Istio 官方的 Demo 来演示,所以本文的大部分内容都可以在官方文档中找到。
如果有感兴趣的同学可以跟着这个 Demo 来实践,但是可能需要一个 K8s 集群,这里推荐使用 Google Cloud Platform 的免费试用服务 GCP Free Tier - Free Extended Trials and Always Free。
当然如果想自己折腾搭建 K8s 集群的同学可以参考笔者的这篇文章 「K8s 学习日记」Kubeadm 部署 kubernetes 集群。
但是笔者还是建议使用谷歌的服务,体验云原生的方式。
Bookinfo 应用分为四个单独的微服务:
productpage. 这个微服务会调用 details 和 reviews 两个微服务,用来生成页面。details. 这个微服务中包含了书籍的信息。reviews. 这个微服务中包含了书籍相关的评论。它还会调用 ratings 微服务。ratings. 这个微服务中包含了由书籍评价组成的评级信息。reviews 微服务有 3 个版本:
ratings 服务。ratings 服务,并使用 1 到 5 个黑色星形图标来显示评分信息。ratings 服务,并使用 1 到 5 个红色星形图标来显示评分信息。下图展示了这个应用的端到端架构。
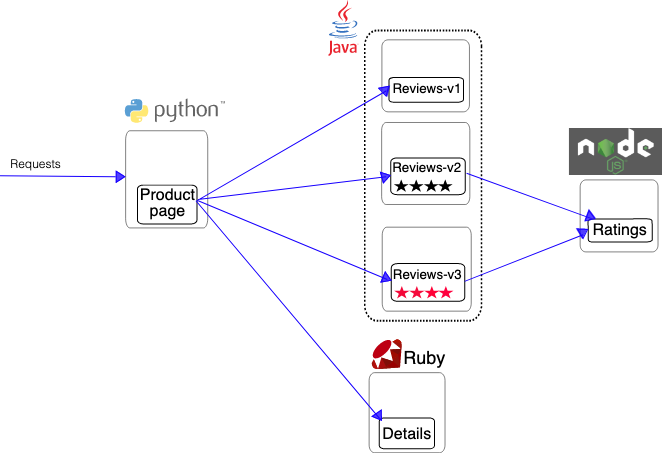
在实际的应用场景中,我们当前发布了两个 Reviews 服务的 feature 版本 v2 和 v3 版本。但是如果需要对这些服务进行测试。
为了开发人员在测试自己开发的 Review 服务不受影响,我们可能需要部署多个完整的 Bookinfo 应用 即 Product page 、 Ratings 、 Details 的服务都需要部署,如下图所示 。
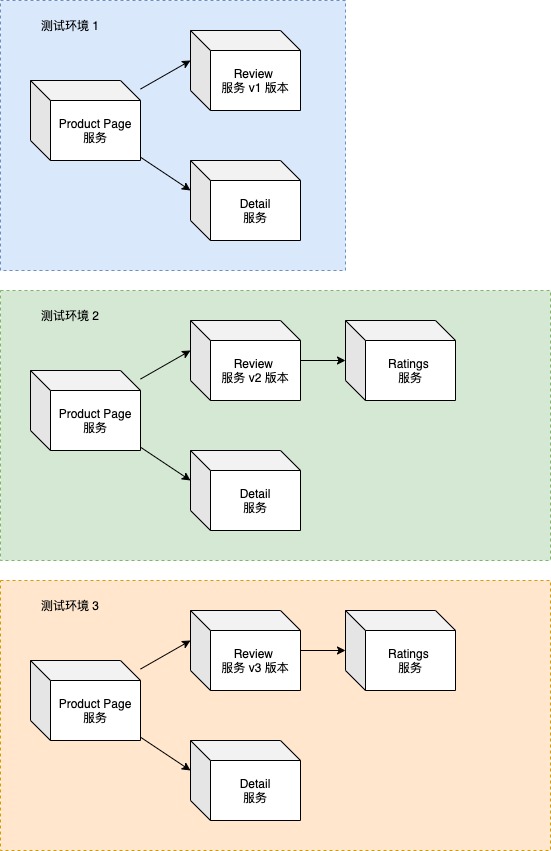
官方的 BookInfo 中的微服务数量还是比较少的,在实际的场景中,一个完整的系统可能会有成百上千个微服务共同支撑和运行,如果为了开发测试方便就需要庞大的服务器资源提供给微服务进行部署,这也是目前笔者公司的一个痛点。
在官方的 demo 中,有这样一个例子。
将来自名为 Jason 的用户的所有流量路由到服务 reviews:v2。将请求头中 end-user 值为 jason
的所有请求指向 reviews:v2 。
正常来说,这样的功能应该需要在具体语言的 Web 框架层进行实现,但是由于 Istio 的 Sidecar 接管了所有的流量,这个功能就在 Istio 中已经集成了。
对于开发人员来时也就是简单的一个配置和一行命令:
$ kubectl apply -f samples/bookinfo/networking/virtual-service-reviews-test-v2.yaml
$ kubectl get virtualservice reviews -o yaml
apiVersion: networking.istio.io/v1alpha3
kind: VirtualService
metadata:
name: reviews
...
spec:
hosts:
- reviews
http:
- match:
- headers:
end-user:
exact: jason
route:
- destination:
host: reviews
subset: v2
- route:
- destination:
host: reviews
subset: v1
当 Istio 的流量控制放到实际的应用场景中时,测试环境就只需要一套完整的服务,和一些需要测试的不同版本的服务了。
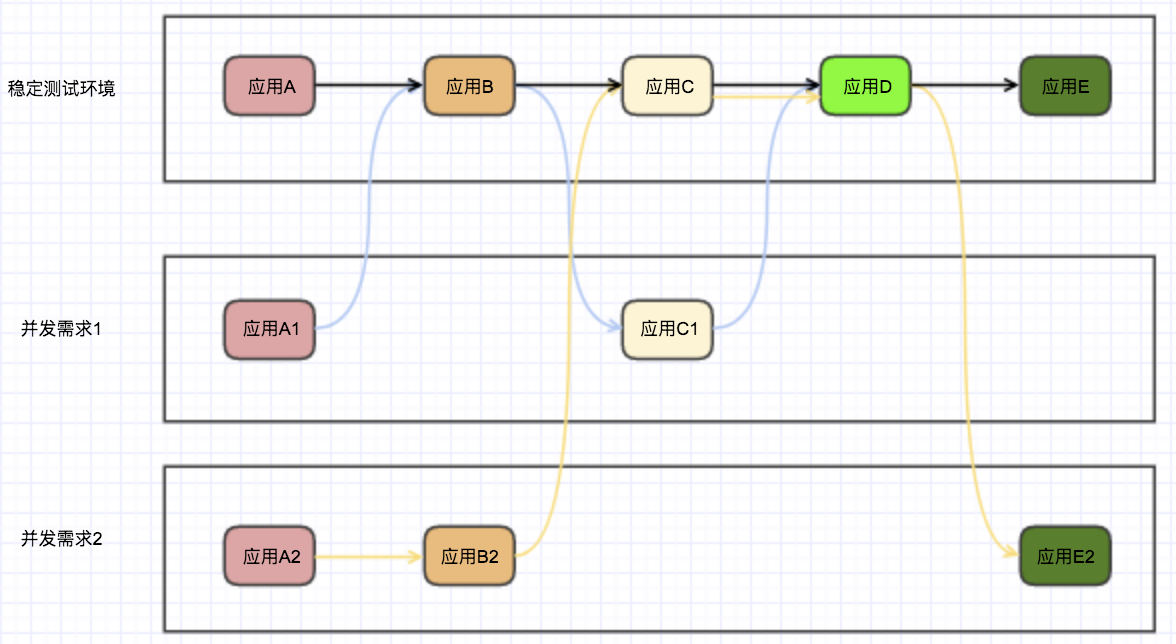
当然这只是其中一个应用场景,流量控制还可以用于 A/B 测试,灰度发布等。并且这只是 Istio 的其中一个功能。
笔者也不一一去介绍 Istio 的其他功能了,如:服务安全、链路追踪、网络拓扑、服务注册等等服务治理相关的功能,感兴趣的同学可以阅读官方文档。
除了官方给出的 demo , 感兴趣的同学还可以在这个网站上找到更多的例子,https://istiobyexample.dev/ 。
以上就是笔者想分享的全部内容,在这个云计算时代,笔者相信 Service Mesh 将会成为微服务架构中的一个佼佼者,帮助我们更好治理微服务架构。
